LLM Tiers
Table of contents
LLM Tiers
An LLM Tier is a classification system that ranks large language models (LLMs) based on their capabilities, performance, and suitability for various applications. These tiers provide a structured way to assess which models are best suited for different tasks, industries, or resource constraints
Key Criteria for LLM Tier Classification
- Performance:
- Reasoning and Comprehension: Ability to perform complex reasoning, understand context, and generate coherent responses.
- Accuracy: Precision in generating relevant and factual outputs.
- Multitask Capabilities: Proficiency across a variety of domains, such as coding, creative writing, and summarization.
- Model Size and Complexity:
- Larger models often perform better but come with higher computational costs.
- Smaller models (e.g., GPT-2) are more lightweight but less versatile.
- Adaptability:
- Ease of fine-tuning and customizing for domain-specific tasks.
- Support for multilingual capabilities or niche applications.
- Cost and Accessibility:
- Compute resources required for training and inference.
- Licensing terms (open-source vs proprietary).
- Specialization:
- General-purpose models (e.g., GPT-4) vs models tailored for specific tasks (e.g., coding-focused models like Codex).
- Benchmarks and Evaluation:
- Performance on standardized NLP benchmarks like GLUE, SuperGLUE, or MMLU.
LLM Tier Breakdown
- S Tier
- The highest-performing models, excelling in a wide range of complex and general-purpose tasks.
- State-of-the-art capabilities, high versatility, advanced reasoning, support for long-context, and multi-modal features.
- A Tier
- High-performing models that approach S Tier but may lack in certain areas like reasoning or scalability.
- Reliable, cost-effective, excellent for business and focused use cases, high-quality outputs, and moderate customization.
- B Tier
- Mid-tier models offering solid performance but limited scalability or generalization.
- Suitable for niche tasks, lower compute requirements, moderate reasoning capabilities, and adequate general-purpose support.
- C Tier
- Entry-level models, typically older generations or smaller architectures.
- Basic capabilities, lightweight, suitable for low-complexity tasks or resource-constrained environments.
- D Tier
- Foundational models, often used for research or experimentation rather than production.
- Minimal capabilities, lightweight, ideal for academic or educational purposes, not recommended for high-performance tasks.
Purpose of LLM Tiering
- LLM tiers help:
- Optimize Model Selection: Match the right model to the task’s complexity, budget, and resource availability.
- Guide Decision-Making: Assist developers, businesses, and researchers in choosing the most suitable model for their goals.
- Set Expectations: Clarify the capabilities and limitations of different models to avoid over- or under-utilization.
LLM Tier Selection Guide
- When to Choose:
- S Tier - Cutting Edge performance
- High Complexity Tasks: Advanced reasoning, multi-step problem-solving, and nuanced decision-making.
- Wide Range of Applications: Versatility for general-purpose use (creative writing, technical tasks, and multilingual content).
- Enterprise-Grade Needs: Tasks requiring reliability, scalability, and state-of-the-art performance.
- Budget is Not a Constraint: These models often come with higher costs for inference and fine-tuning.
- Examples of Use Cases:
- Building conversational AI assistants for large-scale deployments.
- Advanced coding and debugging assistance.
- Scientific research involving complex data analysis.
- Creative industries: screenwriting, art prompts, and ideation.
- A Tier – High Quality and Cost Effective
- Cost-Conscious Applications: Offers a balance between performance and affordability.
- Specialized Tasks: Tasks that don’t demand state-of-the-art precision but require reliable performance.
- Moderate Resource Constraints: Suitable for businesses looking for efficiency without the overhead of S-tier costs.
- Examples of Use Cases:
- Customer service chatbots with domain-specific training.
- Summarization, translation, and sentiment analysis.
- Generating medium-complexity code and providing debugging suggestions.
- Enterprise knowledge bases and search augmentation.
- B Tier – Mid Level Performance for Focused Tasks
- Specific Use Cases: When the focus is on specific tasks like document summarization or text classification.
- Resource Constraints: Suitable for lightweight environments with limited compute or storage.
- Experimentation and Prototyping: Ideal for proof-of-concept development or quick deployment.
- Examples of Use Cases:
- Generating concise summaries for documents or web content.
- Moderate-level question-answering systems.
- Simple chatbot systems or task-specific automation.
- Text generation for blogs or articles where absolute precision isn’t critical.
- C Tier – Entry Level or Lightweight Models
- Basic Applications: Tasks with minimal complexity (e.g., keyword extraction or simple language tasks).
- Low Resource Requirements: Useful in environments with constrained budgets or computing power.
- Training Simplicity: Often used to develop AI systems for educational purposes.
- Examples of Use Cases:
- Academic experiments or teaching materials in NLP.
- Text completion for basic web applications.
- Lightweight analysis of text content.
- Processing short, structured data inputs (e.g., emails).
- D Tier - Foundational/Research Models
- Exploration of NLP Techniques: Ideal for learning and experimenting with model architectures and NLP concepts.
- Resource-Constrained Development: Works well for very lightweight or on-device applications.
- Not Performance Critical: For tasks where accuracy and sophistication are less important.
- Examples of Use Cases:
- Low-compute environments (e.g., edge devices or embedded systems).
- Academic research on language modeling.
- Fine-tuning experiments with smaller datasets.
- Proof-of-concept designs or AI system bootstrapping.
- S Tier - Cutting Edge performance
- Factors to Consider
| Factor | S Tier | A Tier | B Tier | C Tier | D Tier |
|---|---|---|---|---|---|
| Budget | High | Moderate | Low | Minimal | Minimal |
| Performance Needs | Cutting edge | High | Moderate | Basic | Foundational |
| Resource Availability | High | Moderate | Moderate | Low | Very Low |
| Task Complexity. | Complex | Moderate to Complex | Moderate | Basic | Very Basic |
| Customization | Flexible (Fine-tuning) | Flexible (Fine-tuning) | Limited | Limited | Minimal |
LLMs Tier List - 2024
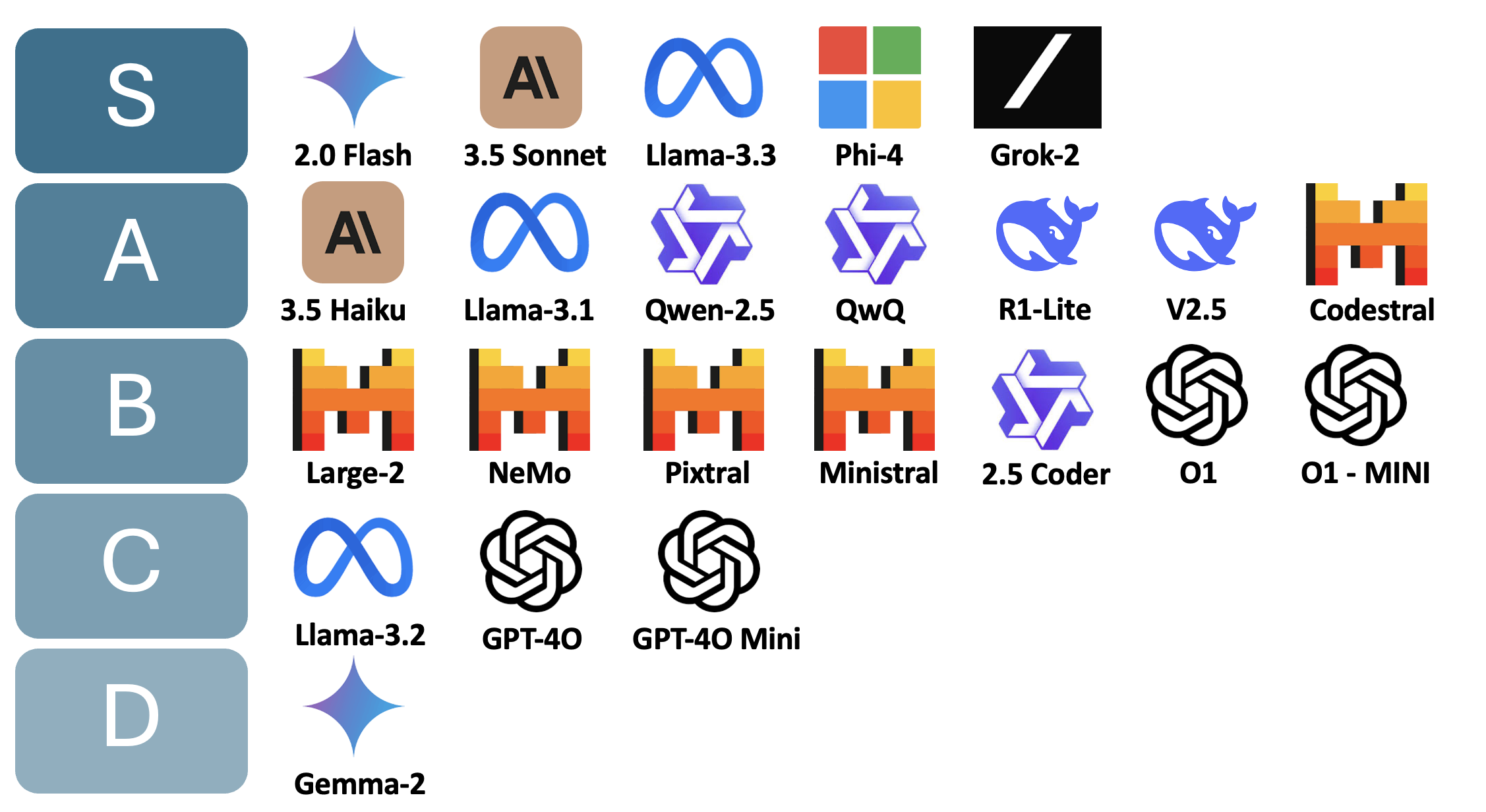
- Gemini 2.0 Flash - Debuting in December 2024, Gemini 2.0 Flash has quickly gained traction as a multimodal powerhouse capable of processing inputs and outputs, including audio. Known for its remarkable speed and zero cost, it rivals GPT-40 in performance while being versatile enough to serve both reasoning and general-purpose needs.
- 3.5 Sonnet - An elite, top-tier model celebrated for its outstanding efficiency and reliability, making it a strong choice for a wide range of applications
- 3.5 Haiku - This model has sparked debate due to its steep price—double that of 3 Haiku. While functional, it doesn’t match the value offered by free models like Gemini Flash or Sonnet, which excel in comparison.
- Mistral Models
- Mistral Large 2: A competent model, although its restrictive licensing may deter some users.
- Mistral Nemo: Once groundbreaking, this collaboration between Mistral and Nvidia has been eclipsed by newer entrants.
- Mistral Pixtral/Ministral: Performance is underwhelming, and its licensing terms leave much to be desired.
- Llama Series: The Open-Source Trailblazers
- 3.1 Models (8B & 405B): These models remain highly effective, with the 405B model holding the title as the largest to date. Licensing is straightforward and user-friendly.
- 3-2 Models: Comprises two mini and two vision models, though the vision models fail to impress.
- 3.3 70B Model: Offers exceptional performance for its size, making it a standout choice.
- Qwen Series
- 2.5: Excels in mathematics and task-specific scenarios but struggles with general knowledge and instruction-following.
- 2.5 Coder: Initially hyped but received criticism for its reliance on proprietary benchmarks.
- QwQ: A strong open-source contender to O1, known for its solid performance
- DeepSeek
- R1-Lite: A capable reasoning model.
- V2.5: Merges coding and general functionalities, delivering excellent performance at a low API cost.
- Phi4: A remarkable entry in the 14B model category, offering substantial power in a compact size.
- OpenAI Models
- GPT-40: While it introduced omni-modality, its delayed feature rollouts allowed Gemini 2.0 Flash to take the lead.
- GPT-40 Mini: Decent performance but overshadowed by Gemini’s more competitive pricing
- O1/O1 Mini: Overpriced at $200 and criticized for its lack of transparency in training processes.
- Gemma 2: Widely regarded as a disappointment due to its poor capabilities
- Codestral: A standout coding model, outperforming Qwen 2.5 in this domain
- Grok-2: An uncensored model praised for its accessibility, available for free via Twitter and API.